
Дубли страниц на сайте: как найти и удалить
Что такое дубли страниц?
Дубли страниц на сайте - это грубая SEO-ошибка, которая характеризуется тем, что контент одной страницы полностью идентичен содержанию другой. Таким образом, они в точности копируют друг друга, но при этом доступны по разным URL-адресам. Это затрудняет индексирование страниц.
Самые частые причины возникновения дублей:
-
Не сделан редирект flhtcjd страниц, имеющих адреса с www и без www. В этом случае каждая страница сайта будет дублироваться, так как остается доступной по двум адресам, например:
http://www.site.ru/page и http://site.ru/page - полные дубли -
Страницы сайта доступны по адресу со слэшем и без слэша:
http://site.ru/page/ и http://site.ru/page -
Также URL страницы может быть с .php и .html на конце либо без расширения. Как правило, это связано с особенностями cms (административной панели сайта):
http://site.ru/page.html и http://site.ru/page; http://site.ru/page.php и http://site.ru/page - Отдельно стоит выделить неполные дубли страниц. В этом случае контент на двух разных страницах не будет идентичным на 100%. Сходство и дублирование может появляться по причине того, что некоторые блоки на сайте являются сквозными - например, это может быть блок о доставке, который отображается на страницах всех товаров.
- Некоторые карточки интернет магазина со схожими товарами содержат идентичное описание, что также может рассматриваться как грубая ошибка.
- Постраничная пагинация каталога с товарами. В этом случае текст и МЕТА-теги на всех страницах одной категории могут быть одинаковыми.
Как дубли влияют на ранжирование?
Дубли негативно влияют на ранжирование вашего сайта в выдаче - за наличие полных дубликатов страниц интернет-ресурс может с большой степенью вероятности подвергнуться пессимизации со стороны поисковых систем.
- Яндекс и Google очень трепетно относятся к уникальности контента на web-ресурсах. В случае, если данные на страницах дублируются, они признаются неуникальными. За это на сайт могут быть наложены санкции.
- Наличие большого количества дублей страниц сильно усложняет процесс индексации сайта и запутывает поисковых роботов.
- Затрудняется продвижение посадочных страниц, так как поисковая система не может выбрать релевантную страницу из двух одинаковых.
- Теряется "вес" страниц, поскольку распределяется между двумя одинаковыми документами.
Подробно описывается негативное влияние дублей и методы борьбы с ними в статье Google "Консолидация повторяющихся URL"
Яндекс, в свою очередь, предлагает на эту тему видеоурок "Поисковая оптимизация сайта: ищем дубли страниц", где разъясняется терминология и способы решения проблемы.
Как обнаружить дубли у себя на сайте?
С поиском дублей могут возникнуть трудности не только у обладателей больших web-ресурсов, но и у владельцев совсем небольших сайтов, так как некоторые дубли, возникающие из-за особенностей и ошибок CMS, очень сложно обнаружить. Быстро и без лишних трудозатрат найти дубли страниц можно с помощью онлайн сервиса Labrika. Для этого нужно просто провести анализ вашего проекта и получить отчет с результатами проверки. соответствующий отчет. Находится он в подразделе "Похожие страницы" раздела "SEO-аудит" в левом боковом меню:
В отчете вы можете увидеть следующую информацию:
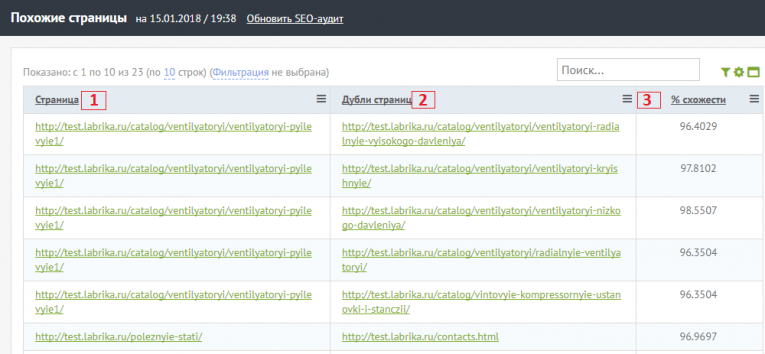
- Страница сайта, которая имеет дубль.
- Дубль этой страницы
- Процент схожести страниц. Благодаря этому проценту вы сможете определить, является ли дубль страницы полным.
Получив данные из отчета, вы сможете сэкономить время и сразу начать устранять эти ошибки.
Как устранить дубли на сайте?
Важно в первую очередь установить характер дубля и уже после этого выбирать способ его устранения.
- Если копий на сайте небольшое количество и их происхождение связано с ошибками CMS (допустим, страница доступна по адресам
http://site.ru/category/tovarиhttp://site.ru/tovar, то самым простым методом решения проблемы будет следующий. Дубль необходимо запретить для индексации поисковых систем вручную в файле robots.txt помощью директивы Disallow, или указать информацию о каноничных страницах с помощью rel canonical (также см. информацию о robots.txt от Google). Затем воспользоваться формой удаления URL из индекса в Яндекс.Вебмастер - https://webmaster.yandex.ru/tools/del-url/ и инструментом аналогичного назначения в Google Search Console - https://www.google.com/webmasters/tools/url-removal. Подробнее про использование инструмента от Google вы можете прочитать здесь. - Если появление дубликатов носит системный характер и связано с такими ошибками, как, например, несклеенный домен (страница доступна по адресу с www и без www), то в таком случае необходимо выбрать главное зеркало (например, адрес сайта без www), воспользоваться командой 301 redirect (перенаправление со страниц с www на страницы без них), которая прописывается в специальном файле htaccess.
- В случае, если вы имеете дело с постраничной пагинацией товаров одной категории, Яндекс советует использовать атрибут rel="canonical". Более подробно о применении этого атрибута на страницах с пагинацией вы можете прочитать в статье Блога Яндекс "Несколько советов интернет-магазинам по настройкам индексирования".