
Скрытая семантика и ее влияние на SEO
Скрытая семантическая индексация (Latent Semantic Indexing — LSI) – это новый метод, который помогает установить соответствие веб-страницы ключевому запросу по наличию на ней слов данной тематики.
Более 30 лет назад было обнаружено, что в естественном языке (речи и литературе) одни слова очень часто употребляются вместе с другими, и выявлены закономерности такого употребления. Спустя десятилетия - начиная с 2011 года - поисковые системы начали использовать метод латентно-семантического индексирования для анализа сайтов, чтобы определить степень релевантности (соответствия) текста поисковому запросу. При этом проверяется контекст употребления ключевых фраз, их семантическое окружение – насколько оно связано по смыслу с ключевым словом и относится к той же тематике.
LSI копирайтинг - что это?
Говоря о скрытой семантике текста (LSI текста), имеют в виду различные словосочетания и отдельные слова, которые обычно употребляются вместе с ключевой фразой внутри одной тематики. То есть в документе должен присутствовать список лексики, релевантной основному ключевому запросу.
К LSI-лексике относятся:
- слова, которые характеризуют и дополняют основную ключевую фразу;
- синонимы основного ключевого слова;
- другие слова, имеющие отношение к теме статьи.
Для чего нужна скрытая семантика
LSI помогает поисковым системам корректно делать три основные составляющие их работы: предоставление всей релевантной информации по запросу, ее уточнение и ранжирование. Страницы проекта, на которых отсутствуют слова из скрытой семантики, не займут высоких позиций в результатах выдачи, так как поисковые системы посчитают их неестественными и не отвечающими в нужном объеме запросу пользователей.
- Наличие в тексте подходящей по смыслу скрытой семантики позволяет поисковым роботам точно определить тематику документа и его релевантность запросу пользователя. Например, отделить друг от друга описание достопримечательностей города Пушкин и биографию известного поэта.
- Поисковые системы применяют LSI (латентно-семантическое индексирование) для борьбы с поисковым спамом – определяют, написан текст для роботов или для людей. В 2017 году Яндекс использовал этот фактор не только для наложения фильтра, но и для ранжирования. Наличие в контенте LSI-лексики позволяет разбавить и оживить текст, снижая тем самым риск попадания сайта под фильтры Яндекса и Google.
- Важно: присутствие скрытой семантики хорошо помогает в продвижении сверх-низкочастотных запросов (список из 0-10 запросов в месяц), которые сложно продвинуть другими способами:
- на такие запросы невозможно накопить поведенческие факторы, так как их запрашивают слишком редко, и статистика по ним не накапливается;
- ссылки с соответствующими анкорами почти не встречаются;
- сверхнизкочастотные запросы могут быть достаточно длинными, поэтому их трудно продвигать с помощью текстов - сложно создать один документ, включающий сразу все слова из такого запроса.
Так что значение скрытой семантики в LSI копирайтинг весьма велико – только она помогает поисковым системам установить соответствие ресурса запросу пользователя, и чем больше ее будет использовано, тем более высокую позицию в выдаче займет продвигаемая страница.
Как собрать скрытую семантику?
Самые простые и быстрые способы широко описаны в интернете и предлагают собирать скрытую семантику для копирайтинга из поисковых подсказок, сниппетов и похожих запросов в блоке рекомендаций на поисковой странице.
Но все эти способы не дают возможность собрать всю подходящую по тематике лексику. Поисковые подсказки, например, показывают то, что еще обычно ищут люди с этим запросом, а не слова, которые чаще всего употребляется вместе на одной странице. Хотя частично пересечения с настоящей скрытой семантикой там, конечно, встречаются и, при отсутствии более эффективных способов сбора, этот метод даёт некоторый результат.
Поисковые подсказки могут оказаться бесполезными для подбора LSI-слов по сверх-низкочастотным запросам, так как по ним подсказки бывают не всегда. И это при том, что как раз для сверх-низкочастотных запросов скрытая семантика имеет наибольшее значение.
Сбор по похожим запросам имеет те же самые недостатки. Поиск по сниппетам также не позволяет собрать все слова, так как сниппеты формируются чаще всего из title и description, ограничены по размеру и не включают в свой состав основной текст.
Сервис для продвижения сайтов Labrika использует для сбора LSI-слов тот же способ, что и поисковые системы - семантический анализ - обрабатывает большое количество естественных текстов. Поэтому точность подбора скрытой семантики у Labrika будет заведомо выше.
Как правильно использовать LSI-слова?
Использование LSI текста является необходимым условием успешного ранжирования. Необязательно использовать все собранные слова, однако чем больше присутствует в тексте синонимов ключевой фразы, соответствующих ей по смыслу слов и словосочетаний, тем выше вероятность того, что данные тексты поисковые системы будут показывать в списках выдачи по разным запросам.
Стратегия работы со скрытой семантикой:
- При написании текста по правилам LSI копирайтинга, рекомендуется употреблять не менее половины слов из скрытой семантики
- Если сайт оказался под текстовым фильтром, необходимо убрать весь переспам на страницах и добавить LSI-слова
- Обязательно используйте скрытую семантику для оптимизации сверх-низкочастотных запросов
Использование скрытой семантики для характеристики товара в интернет-магазине
Наличие слов из скрытой семантики в описании товара помогает поисковой системе в ответ на запрос пользователя найти страницу данного товара в каталоге интернет-магазина и отличить ее от SEO-текста, в котором нет конкретных характеристик.
Например, для запроса «купить постельное белье из сатина»
Лабрика рекомендует использовать следующие слова из скрытой семантики:
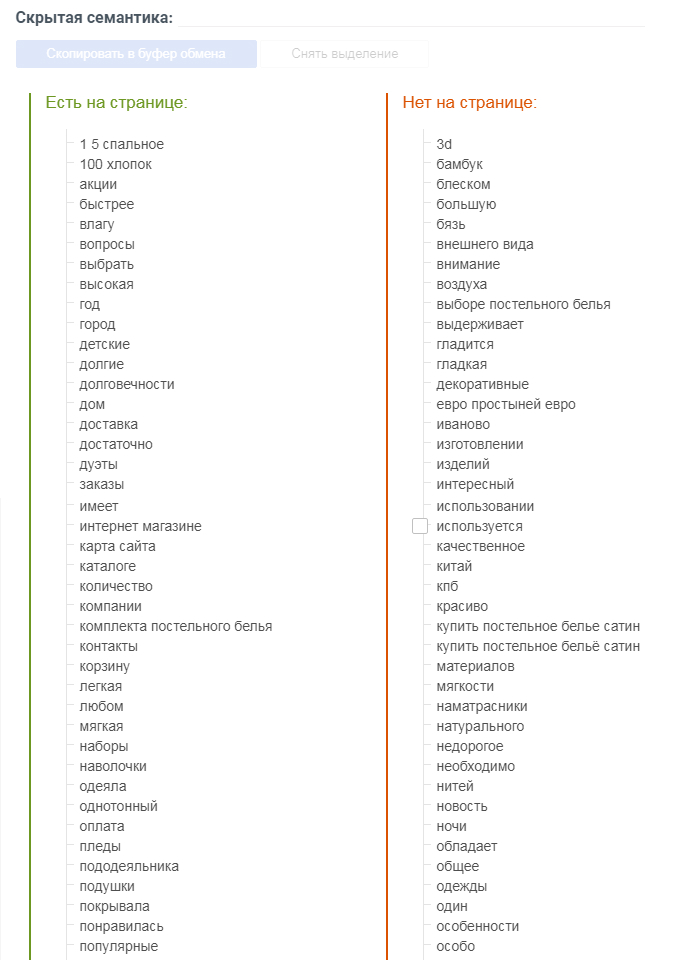
Использование слов из скрытой семантики на странице товара в каталоге интернет-магазина:
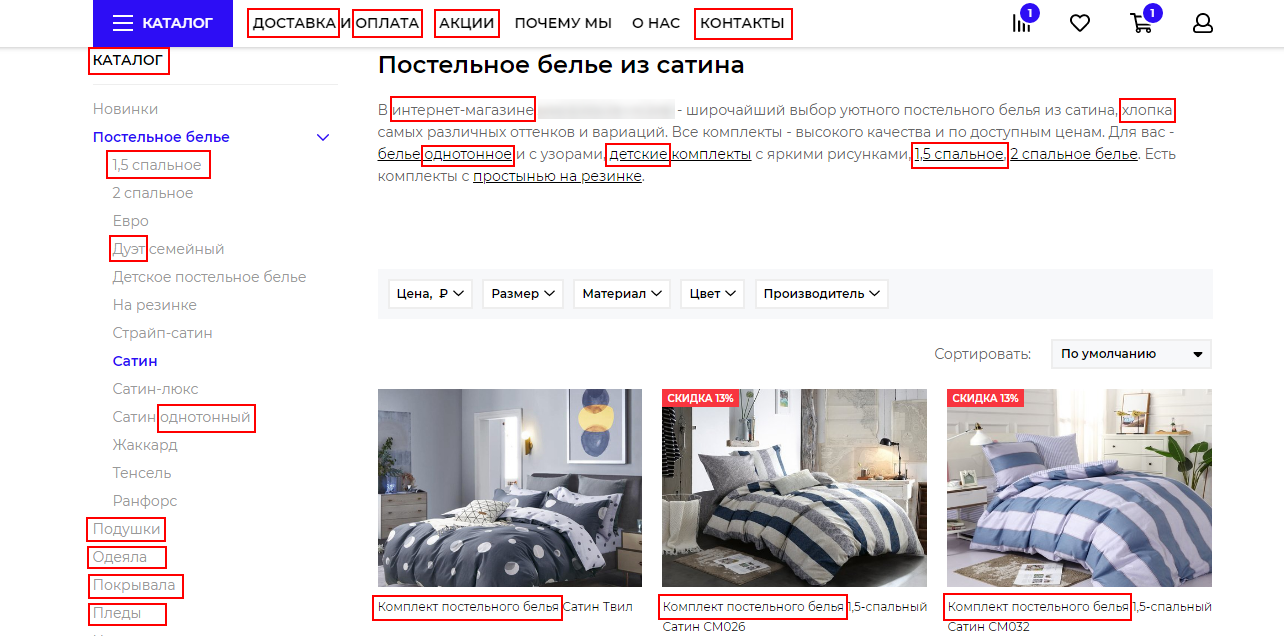

Использование скрытой семантики для продвижения агрегаторов
Преимущество сайтов-агрегаторов заключается в предоставлении ими пользователю большого выбора товаров и услуг от разных компаний. Эта особенность позволяет таким сайтам занимать высокие позиции в выдаче поисковой машины даже без размещения на посадочных страницах SEO-текстов, оптимизированных под ключевые запросы. Для успешного продвижения им достаточно использовать все необходимые слова из скрытой семантики (размеры изделий и др.) на карточках множества представленных товаров.