
Исправляем ошибки и правильно настраиваем файл robots.txt
Robots.txt - это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие - нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Почему robots.txt важен для SEO-продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Например:
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
Какие директивы используются в robots.txt
User-agent
User-agent - основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow - принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* - спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: *
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
$ - знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: *
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'
Crawl-delay
Crawl-delay - директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param:
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap - это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt:
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет "Ошибки robots.txt " находится в разделе "Технический аудит" левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
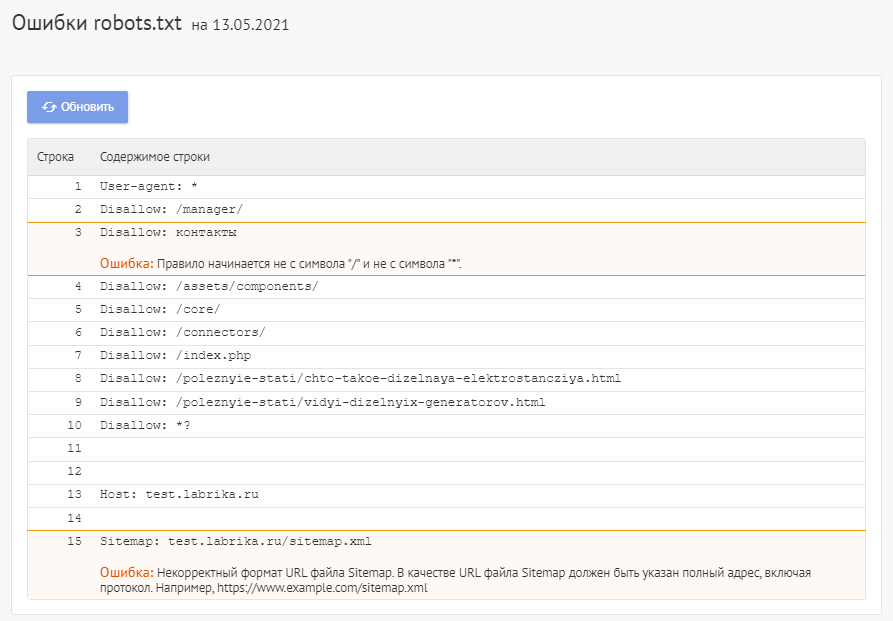
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом ":".
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent, поскольку она указывает, для какого поискового робота предназначены инструкции.
Пример:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть "не запрещать ничего".
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида "User-agent: *"
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример:
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле - 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак "$" можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа "/" и не с символа "*".
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Пример:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
С марта 2018 года Яндекс отказался от директивы Host. Вместо неё используется раздел «Переезд сайта» в Вебмастере и 301 редирект.
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив
Crawl-delay; - некорректный формат директивы
Crawl-delay.
Пример:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд "&" подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду "p0[&p1&p2&..&pn] [path]". В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: ".", "-", "/", "*", "_".
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark - маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать - открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt, следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.