
Индексный блоат и SEO оптимизация
Индексация - это процесс анализа страниц сайта поисковыми системами и внесение информации о них в индекс (базу данных) для последующего использования её в ранжировании и формировании результатов поиска. Индексация осуществляется с помощью краулера (поискового робота).
Раздуванием индекса называют занесение в индекс поисковой системы большого количества страниц, которые не представляют ценности для пользователей и могут отрицательно сказаться на ранжировании сайта. Это, например:
- служебные и технические страницы (страницы команд, тестовые страницы и др.);
- страницы тегов блога (в WordPress);
- страницы категорий блога;
- страницы авторов блога;
- страницы архивов;
- старые новости и пресс-релизы;
- тощие целевые страницы (менее 50 слов);
- автоматически созданные профили пользователей;
- страницы с благодарностями;
- страницы результатов поиска по сайту и т.д.
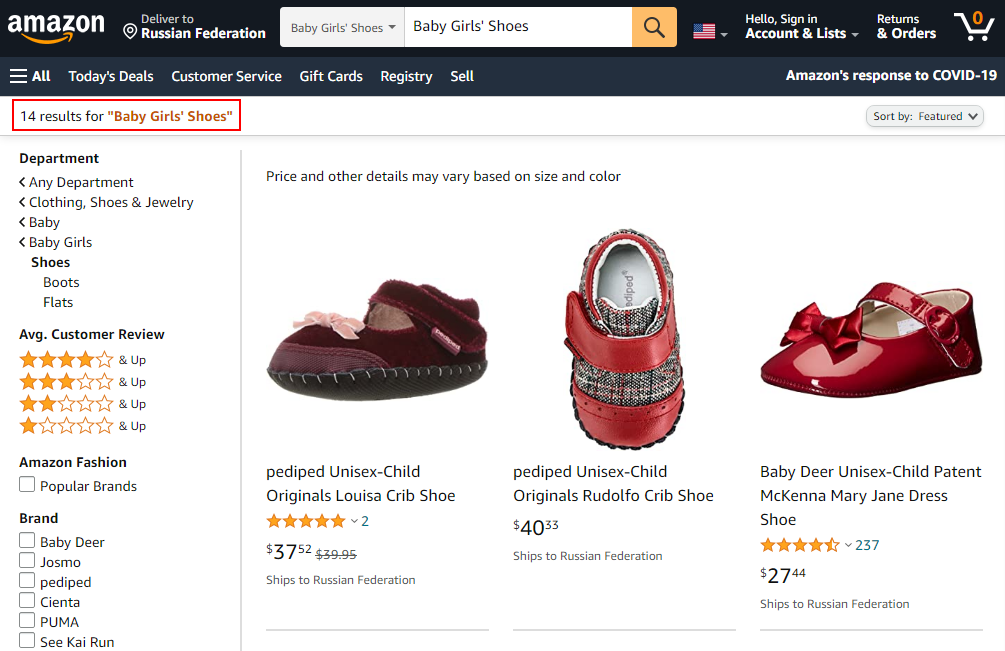
Проблема раздутого индекса часто встречается на сайтах электронной коммерции с большим количеством товаров и категорий, с фильтрами и сортировкой. Технические ошибки могут привести к появлению множества дублей страниц. В этом случае генерируется большое количество комбинаций URL-адресов, которые в итоге попадают в индекс.
Например, известен случай, когда из-за неправильной настройки программного обеспечения и фильтров каталога 500 карточек товаров дали более 30 тысяч дубликатов. Добавление в корзину, различное отображение каталога, сравнение товаров, сортировка и постраничная разбивка многократно умножали все варианты показа одной и той же информации.
Почему важно знать о раздувании индекса?
Раздутый индекс заставляет поисковых роботов тратить слишком много времени на сканирование ненужных страниц вместо того, чтобы индексировать полезные для вашего бизнеса страницы, которые могут так и не попасть в результаты поиска. В итоге замедляется обработка сайта поисковыми системами, впустую расходуется ценный краулинговый бюджет (лимит, выделенный на индексацию конкретного веб-ресурса), а сайт теряет позиции в результатах поиска.
Кроме того, это создает неудобства для пользователей - они попадают на страницы низкого качества и не получают нужной информации. Это, в свою очередь, приводит к ухудшению поведенческих факторов, снижению продаж и других целевых действий.
Как обнаружить проблему?
Начните с проверки общего количества проиндексированных страниц. Сервис Labrika покажет в отчете по сводному техническому аудиту сайта количество его страниц, включенных в индекс Google или другой поисковой системы, которую вы указали в настройках сервиса. Динамика показателей отображается на графике.
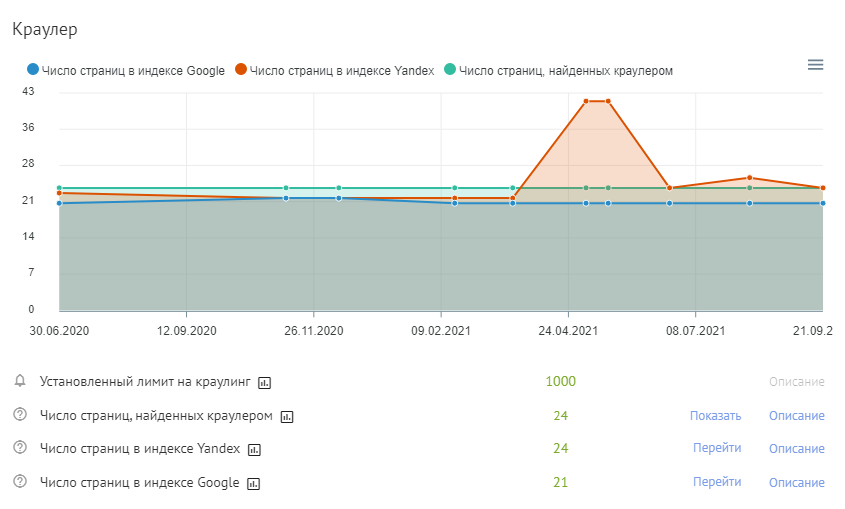
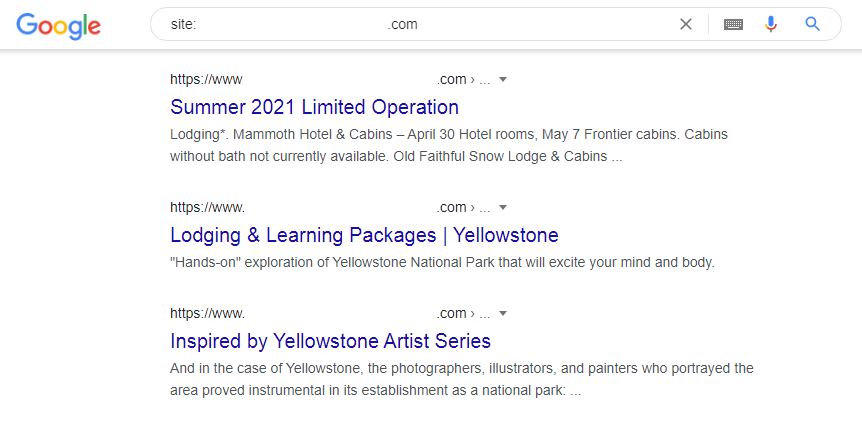
При клике по ссылке “Перейти” откроется страница результатов поиска по запросу site:website.com, где будут указаны URL-адреса сайта, которые находятся в индексе данной поисковой системы.
Если вы замечаете резкое увеличение количества проиндексированных страниц на своем сайте, это может быть признаком проблемы раздутого индекса.
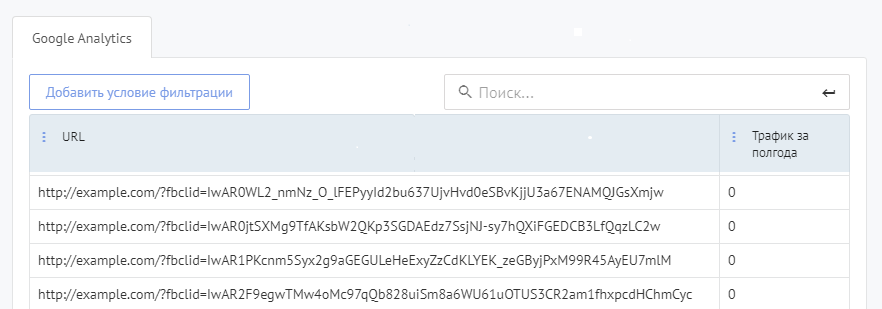
Чтобы выявить неэффективные страницы, воспользуйтесь отчетом Страницы без трафика в разделе поведенческих факторов. Он показывает страницы, на которые пользователи не заходили в течение 6 месяцев. Посмотрите их – это могут быть страницы с ошибкой 404 или другими техническими проблемами, дубли, страницы с малополезным контентом.
Проверьте наличие на сайте так называемых «тощих» страниц. Тощими называются страницы с очень маленьким объемом текста (менее 150 слов) или даже совсем без текста, которые поисковые системы могут посчитать бесполезными. Такие страницы имеют низкую ценность и практически не ранжируются.
Кроме этого, они дают большой процент ухода пользователей с сайта. Исключениями могут быть страницы с видео или страницы из портфолио дизайнерских компаний.
Найти тощие страницы можно с помощью соответствующего отчета в разделе «SEО-аудит» на Labrika.
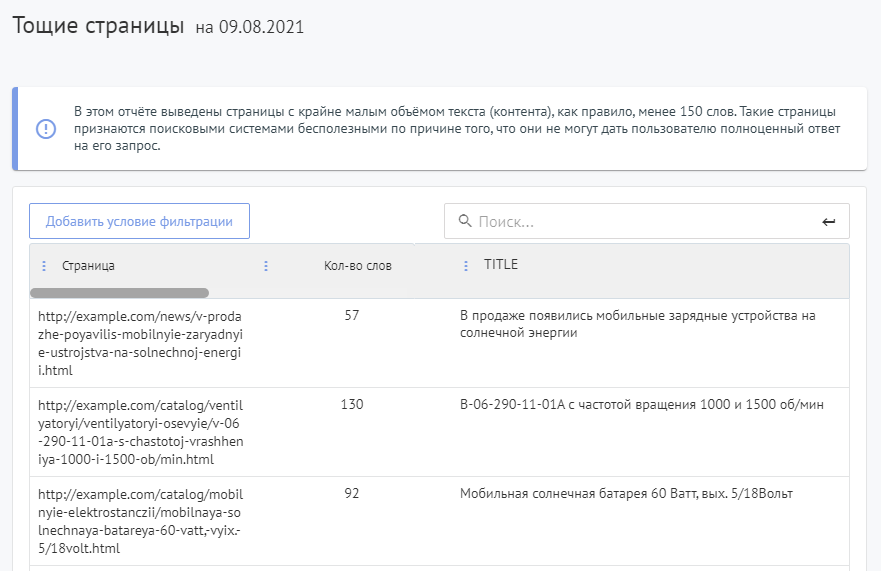
Вы можете перейти по каждой ссылке и проверить отображаемые в отчете страницы на информативность и полезность. Например, если при нажатии на картинку она открывается в увеличенном виде на новой странице - такие страницы не нужны.
Как исправить раздувание индекса?
После того, как вы определили малоэффективные страницы, которые могут раздувать индекс, у вас есть несколько вариантов решения проблемы.
Удалите ненужные страницы и сделайте переадресацию
Если у вас на сайте большое количество устаревших или тощих страниц с малополезным содержимым, которые вы больше не используете, которые не генерируют трафик и не приводят к конверсиям, удалите их и настройте переадресацию (через 301-й редирект) на другие страницы с подходящим контентом.
Так вы не потеряете авторитет от обратных ссылок, ведущих на удаленные страницы, и уменьшите количество ошибок 404, которые отдают несуществующие страницы.
Заблокируйте индексацию страниц, не подходящих для отображения в результатах поиска
Не все страницы вашего сайта подходят для индексации. Как правило, от поисковых систем закрывают не предназначенную для пользователей информацию, которую не следует показывать в поисковой выдаче.
Чаще всего запрещают индексировать разного рода техническую, служебную и конфиденциальную информацию, При продвижении коммерческого сайта оптимизаторы закрывают от индексации личные кабинеты пользователей, корзину, сравнение товаров, дубли страниц, результаты внутреннего поиска по сайту и т. п.
Как предотвратить индексацию страниц
Запретить индексировать страницы вашего сайта можно по-разному - ниже приводятся несколько простых способов.
Используйте атрибут noindex в метатеге robots
Чтобы заблокировать индексацию страницы, поместите метатег robots с этим атрибутом в раздел <head> HTML-кода страницы, например:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
Значение name «robots» в приведенном примере указывает, что директива не индексировать страницу применяется ко всем поисковым роботам.
Чтобы предотвратить индексирование вашей страницы только роботом Googlebot, запишите тег следующим образом:
<meta name="googlebot" content="noindex" />
Укажите канонические страницы
Каноническая страница - это страница сайта, которая является предпочтительной для индексации в поисковых системах. Для указания поисковым системам канонической страницы применяется атрибут rel="canonical". То есть, когда поисковый робот находит этот атрибут на какой-либо странице, он индексирует не её, а ту страницу, прописанную в атрибуте.
Указание канонической страницы необходимо, когда документы с идентичным содержанием можно найти по разным адресам – это позволяет избежать точных дублей в индексе поисковой системы. Например, если товар имеет несколько размеров и полностью совпадающее описание, убедитесь, что на карточках с вариантами продукта указана предпочтительная для индексации каноническая страница.
Прописывается атрибут rel="canonical" в блоке <head> HTML-кода страницы следующим образом:
<link rel=”canonical” href=”канонический URL” />
Где «канонический URL» – это полный адрес страницы, которую вы считаете предпочтительной для индексации. Например:
<link rel=”canonical” href=”http://site.ru/razdel/document/"/>
Подробнее о канонических URL вы можете прочитать в отдельной статье нашего сайта.
Добавьте в файл robots.txt директиву «Disallow»
Robots.txt - это специальный файл в корневом каталоге сайта, в котором приводятся рекомендации для поисковых роботов о том, какие страницы можно сканировать, а какие не следует.
Чтобы заблокировать страницу в robots.txt, необходимо воспользоваться директивой «Disallow», указав страницу после косой черты:
User-agent: * Disallow: /private_file.html
Можно запретить сканирование определенной группы страниц и файлов. Например, чтобы заблокировать индексацию страниц и файлов, начинающихся с '/cart', следует прописать:
Disallow: /cart
URL-адреса, запрещенные файлом robots.txt, могут индексироваться и отображаться в поиске и без сканирования. Например, поисковые системы могут по-прежнему ссылаться на заблокированные вами URL-адреса (показывая только URL, без заголовка или описания), если где-то в Интернете есть ссылки на эти страницы.
Заблокируйте ссылки, которые ведут на страницу
Закройте переход краулера по ссылке на страницу при помощи атрибута nofollow:
<a href="/page" rel="nofollow">текст ссылки</a>
Имейте в виду, что страница будет закрыта от индексации, только если все ссылки на неё будут заблокированы. При наличии хотя бы одной незакрытой ссылки краулер поисковой системы перейдет по ней и проиндексирует страницу.
Воспользуйтесь инструментом удаления URL-адресов в Google Search Console
Добавление директивы noindex может не дать быстрого результата, и Google еще какое-то время будет индексировать страницы. В этом случае целесообразно воспользоваться инструментом удаления URL-адресов. Хотя данный метод носит временный характер, при его использовании страницы удаляются из индекса Google быстро (обычно в течение нескольких часов в зависимости от количества запросов).
Обновите полезные страницы, получающие мало трафика
Чтобы в индексе находились только полезные страницы, нужно также исправить те, которые имеют ценное содержимое, но не получают трафика. Например, можно принять следующие меры:
- оптимизировать мета-теги Title и Description, заголовки и контент, чтобы страница лучше соответствовала запросу;
- исправить на странице грубые технические и SEO ошибки;
- объединить с другими страницами, посвященными той же теме;
- добавить ссылки с подходящих по тематике авторитетных страниц вашего сайта – например, со страниц товарных категорий, с карточек похожих или дополняющих товаров и т. п.;
- организовать навигацию на сайте таким образом, чтобы направить больше трафика на нужные страницы.
Убедитесь, что на всех проиндексированных страницах есть ценное для пользователей уникальное содержимое. Если в индекс поисковой системы попадет множество страниц с тощим или одинаковым контентом, это может привести к пессимизации сайта.
Отправьте сайт на переиндексацию
Как переиндексировать сайт в Яндексе
Чтобы изменения вашего сайта быстрее отразились в результатах поиска Яндекса, сообщите об этом индексирующему роботу с помощью инструмента Яндекс.Вебмастер:
- В боковом меню Яндекс.Вебмастера на выберите раздел «Индексирование» → «Переобход страниц».
- В поле укажите адрес обновленной страницы.
- Нажмите кнопку «Отправить».
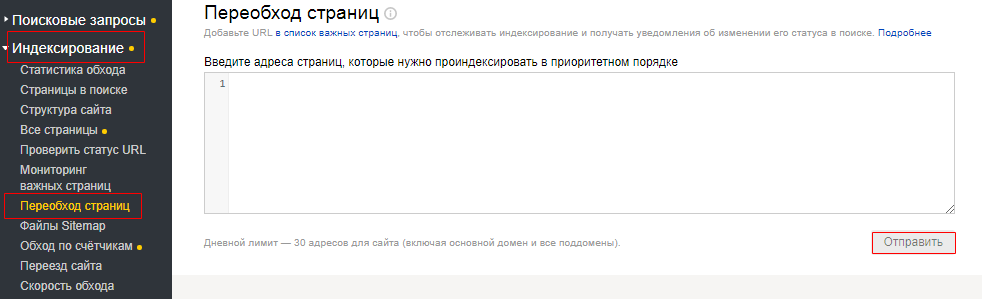
Робот Яндекса посетит указанный вами адрес в приоритетном порядке при следующем обращении к сайту. Если вы отправили на переобход страницу, которая ранее уже была в индексе, изменения отобразятся в результатах поиска при очередном обновлении поисковой базы — в течение двух недель.
Отправка на переобход (переиндексацию) страницы в Google Search Console
Переобход страниц в Google Search Console позволяет при наличии изменений на странице отправить их в поисковую систему Google путем повторного сканирования.
Для этого выберите на левой панели сервиса раздел «Проверка URL» и введите URL-адрес нужной страницы в поисковое поле сверху. Затем необходимо кликнуть на кнопку «Запросить индексирование».
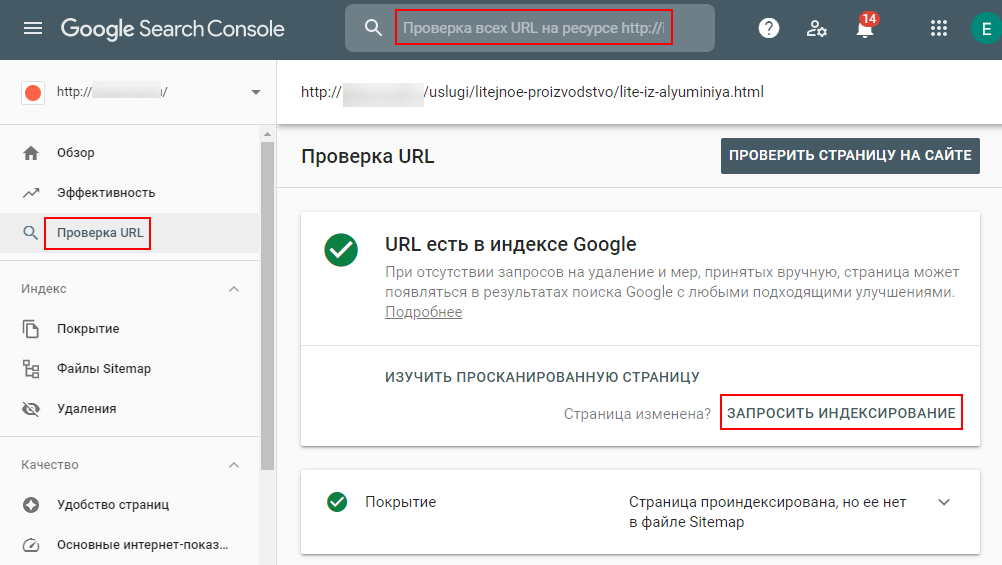
Инструмент проверит страницу на наличие проблем с индексированием. Если таковые не обнаружатся, страница будет добавлена в очередь на индексирование.
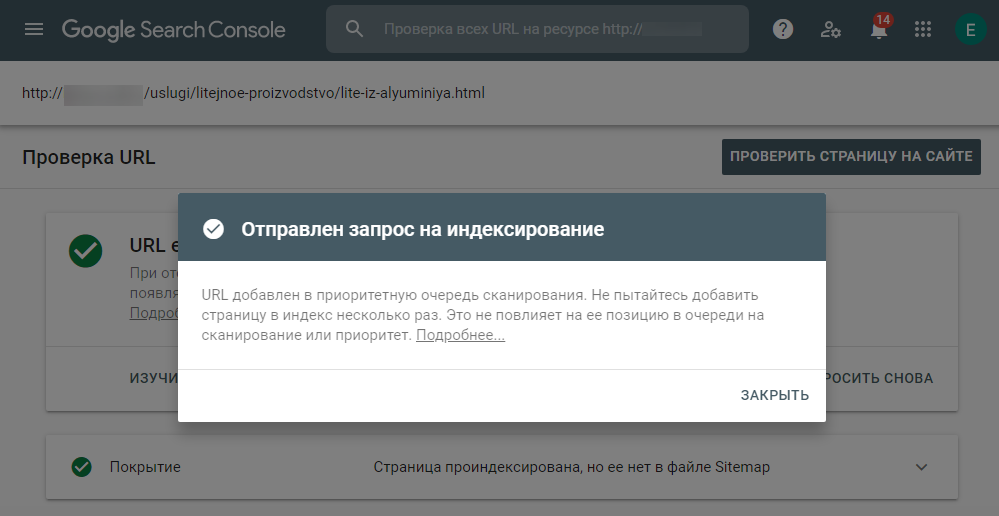
После этого в течение 1-2 дней робот вновь просканирует отправленный на переобход URL и внесет изменения в базу.
Чтобы ваш сайт оставался функциональным и полезным ресурсом, регулярно проводите аудит его состояния, проверяйте актуальность контента. Следите, чтобы в индекс не попадали ненужные документы. Это позволит поисковым системам быстро находить те страницы, которые вы продвигаете, улучшить оценку качества вашего сайта и повысить его позиции в результатах поиска.