Блокировки индексации
Индексация - это процесс анализа страниц сайта поисковыми системами и внесение информации о них в индекс (базу данных) для последующего использования её в ранжировании и формировании результатов поиска.
Индексация осуществляется с помощью краулера (поискового робота).
Зачем нужны блокировки от индексации?
Как правило, от поисковых систем закрывают информацию, которая не должна отображаться в поисковой выдаче. Чаще всего это разного рода техническая, служебная и конфиденциальная информация, страницы с непригодным для размещения в результатах поиска содержанием. Например, при продвижении коммерческого сайта оптимизаторы запрещают для индексации личный кабинет пользователей, корзину, сравнение товаров, дубли страниц, результаты поиска внутри сайта, и т. п.
Иметь информацию о таких страницах необходимо уже потому, что некоторые из них могут быть закрыты по ошибке.
Виды блокировок от индексации
Существует множество способов запретить индексацию страниц:
-
С помощью файла robots.txt
Robots.txt - это специальный текстовый файл, в котором приводятся рекомендации для поисковых систем о том, какие страницы можно индексировать, а какие не следует.
Чтобы заблокировать страницу от индексации в robots.txt, необходимо воспользоваться директивой Disallow.
Пример:
# Содержание файла robots.txt,# который обязательно должен находиться в корневом каталоге сайта# Задаём директиву, что дальше идут правила для робота ЯндексаUser-agent: Yandex# разрешаем индексацию страниц и файлов, начинающихся с '/catalog'Allow: /catalog# блокируем индексацию страниц и файлов, начинающихся с '/cart'Disallow: /cart
-
При помощи тега
<meta>robots с атрибутом noindex.Чтобы заблокировать страницу с помощью этого атрибута, необходимо добавить в раздел страницы
<head>следующие строчки:# заблокировать страницу от индексации целиком# строка должна размещаться в блоке <head> на самой странице<meta name="robots" content="noindex">
-
При помощи закрытия от индексации ссылок, которые ведут на нужную страницу.
Существует 2 способа это сделать.
-
Закрыть переход краулера по конкретной ссылке:
# Блокировка перехода краулера по конкретной ссылке на страницу /page# блокируется непосредственно ссылка<a href="/page" rel="nofollow">текст ссылки</a>
Имейте в виду, что страница при этом способе будет заблокирована от индексации, только если все ссылки на неё будут заблокированы. Так как если останется хотя бы одна незакрытая ссылка, то краулер поисковой системы перейдет по ней и проиндексирует страницу.
-
Закрыть переход краулера по всем ссылкам на странице:
# Блокировка перехода краулера по всем ссылкам на странице,# при этом, если мы не добавили директиву noindex, то сама страница будет проиндексирована# строка должна размещаться в блоке <head> на самой странице<meta name="robots" content="nofollow" />
-
-
Также можно закрыть страницу от какой-либо конкретной поисковой системы прямо в заголовке HTML страницы, например:
# строка должна размещаться в блоке <head> на самой странице заблокировать страницу от индексации в Google<meta name="googlebot" content="noindex"># заблокировать страницу от индексации в Yandex<meta name="yandex" content="noindex" />
Можно использовать комбинации директив:
# строка должна размещаться в блоке <head> на самой странице# заблокировать страницу от индексации в Google, но перейти по ссылкам дальше, чтобы проиндексировать страницы глубже<meta name="googlebot" content="noindex, follow"># в Yandex страницу разрешить для индексации, но по ссылкам дальше не переходить<meta name="yandex" content="index, nofollow" />
Еще вариант:
# строка должна размещаться в блоке <head> на самой странице# заблокировать страницу от индексации в Yandex, и заблокировать переход краулера по ссылкам<meta name="yandex" content="none"># строка будет аналогична строке:<meta name="yandex" content="noindex, nofollow" />
-
Прописать каноническую страницу:
Атрибут
rel=canonicalприменяется для указания поисковым системам канонической страницы. Каноническая страница - это страница сайта, которая является предпочтительной для индексации в поисковых системах. То есть, когда поисковый робот находит этот атрибут на какой-либо странице, он индексирует не ее, а ту страницу, которая указана в атрибуте. В отличие от редиректа,rel=canonicalпереадресует на другую страницу не пользователей, а только поисковые системы.Указание канонической страницы необходимо, когда документы с идентичным содержанием можно найти по разным адресам. Это позволяет избежать точных дублей в индексе поисковой системы и не попасть под фильтр.
Например, когда у вас страница с одним содержанием для разных устройств:
https://example.com/news/https://m.example.com/news/https://amp.example.com/news/
Или когда на странице несколько видов сортировок:
https://example.com/catalog/https://example.com/catalog?sort=datehttps://example.com/catalog?sort=cost
Если товар имеет несколько размеров, и полностью идентичное описание:
https://example.com/catalog/shirthttps://example.com/catalog/shirt?size=XLhttps://example.com/catalog/shirt38
Прописывается атрибут
rel=canonicalследующим образом:# строка должна размещаться в блоке <head> на самой странице<link rel="canonical" href="https://example.com/catalog/shirt"/>
-
Также можно передать каноническую страницу в заголовке HTTP-запроса.
Внимание! При таком способе передачи вы не сможете увидеть эту блокировку без специального программного обеспечения или плагинов!
# передаётся в заголовке страницы. Браузер без специальных плагинов не показывает HTTP заголовки пользователямHTTP/1.1 200 OKLink: <https://example.com/catalog/shirt>; rel=“canonical”
Подробнее про канонические страницы читайте в документации Google.
-
При помощи заголовка HTTP-запроса "X-Robots-Tag" для определенного URL:
Внимание! При таком способе передачи вы не сможете увидеть эту блокировку без специального программного обеспечения или плагинов!
# передаётся в заголовке страницы. Браузер без специальных плагинов не показывает HTTP заголовки пользователямHTTP/1.1 200 OKX-Robots-Tag: yandex: noindex
Как обнаружить на сайте заблокированные от индексации страницы?
Посмотреть данные обо всех страницах вашего сайта с блокировкой от индексации вы можете в разделе "SEO-аудит" -> "Блокировки индексации".
На странице отчета можно отфильтровать результаты и проверить только блокировки посадочных страниц. Для этого нужно кликнуть по кнопке «Блокировки посадочных».
Содержание отчёта:
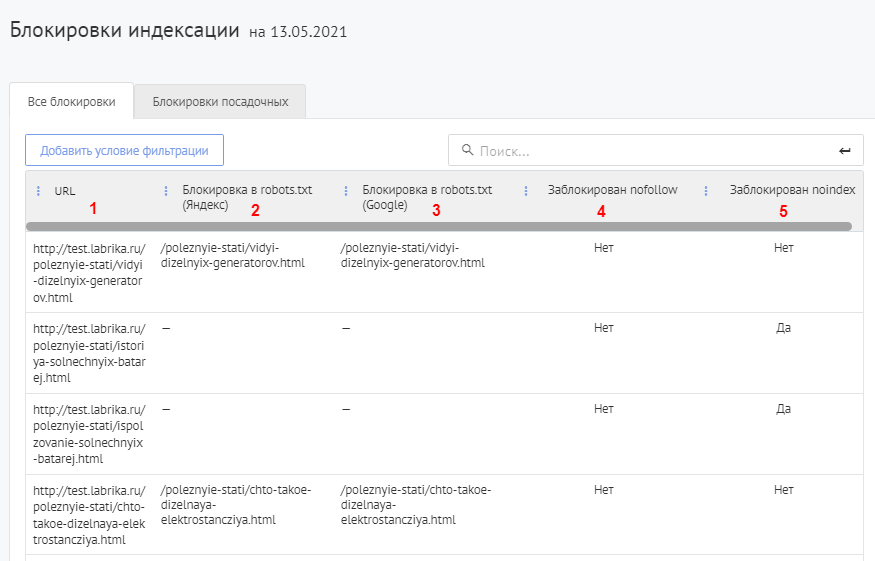
- Адреса страниц, закрытых от индексации;
- Директива в robots.txt, если страница заблокирована этим способом от индексации в Яндексе;
- Директива в robots.txt, если страница заблокирована этим способом от индексации в Google;
- Блокировка ссылок на страницу при помощи атрибута nofollow;
- Блокировка страницы при помощи атрибута noindex.
Как убрать блокировку?
Во многих современных системах управления сайтом (CMS) можно изменить файл robots.txt, метатеги rel=canonical и robots. Поэтому для внесения изменения необходимы только знания принципов блокировок индексации. В противном случае для внесения изменений потребуется разработчик. Если схема блокировок на сайте сложная, то рекомендуется сначала составить графическую схему, чтобы избежать ошибок.
Вопросы-ответы
-
Почему Лабрика показывает, что страница заблокирована, но она есть в индексе поисковых систем?
Это может случиться в следующих случаях:
-
Страница была закрыта недавно, и поисковая система еще не успела внести изменения в свой индекс.
-
Эта страница закрыта от индексации, но добавлена в карту сайта sitemap.xml. Яндекс чаще всего индексирует такие страницы, а Google - нет. При этом, несмотря на то, что страница есть в индексе поисковых систем, ее вес (PageRank) будет равен 0, так как ссылок на страницу не найдено. А значит, вероятность попадания в ТОП-10 результатов поиска данной страницы крайне мала.
-
На эту страницу есть внешние ссылки - с других сайтов.
Внимание! Если прошло некоторое время, то отчёт может отличаться от реального положения дел, так как на сайт уже могли быть внесены изменения. Держите отчёты в актуальном состоянии.
-